Bagging
Bootstrap Aggregation famously knows as bagging, is a powerful and simple ensemble method.
What are ensemble methods?
Ensemble learning is a machine learning technique in which multiple weak learners are trained to solve the same problem and after training the learners, they are combined to get more accurate and efficient results.
weak learners + weak learnersn = Strong learner
An ensemble method is a technique that combines the predictions from many machine learning algorithms together to make more reliable and accurate predictions than any individual model. It means that we can say that prediction of bagging is very strong.
Why we use bagging?
The main purpose of using the bagging technique is to improve Classification Accuracy.
How does Bagging work
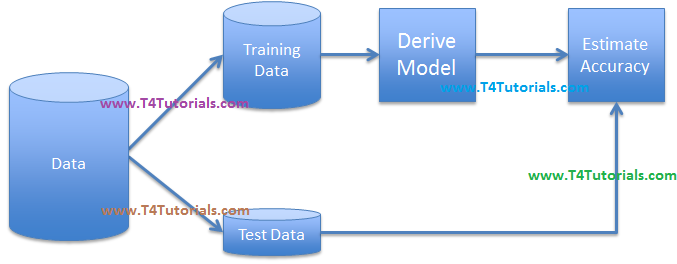
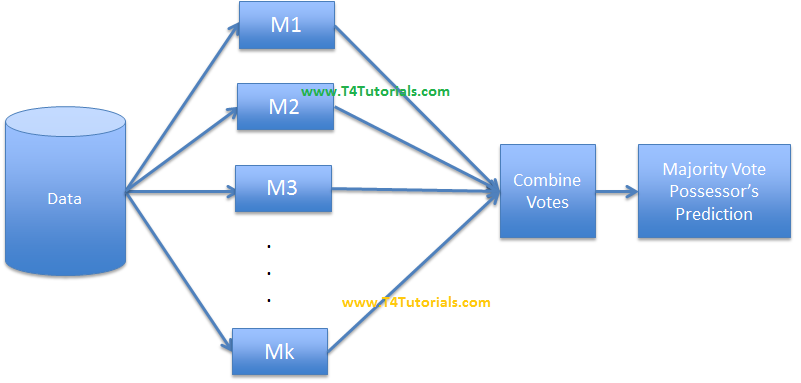
For example, we have 1000 observations and 200 elements. In bagging, we will create several models with a subset of variables and a subset of observations. i.e we might create 300 trees with 300 random variables and 20 observations in each tree. After that, we can average the results of all the 300 tree’s (models) to get to our final prediction.
Model’s Derivation/Estimation (In General)
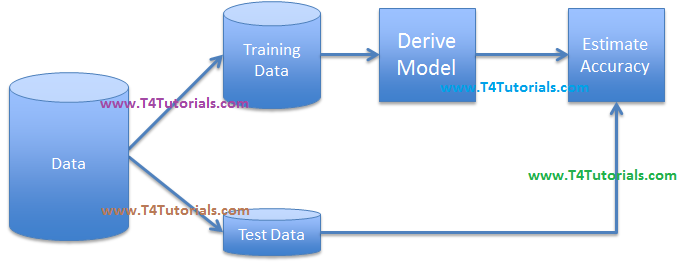
Bootstrap
- Accuracy Estimation
- Sampling with replacement
- Some may not be used, other may be used more than once
Bootstrap – At Abstract

Bootstrapping – in Detail
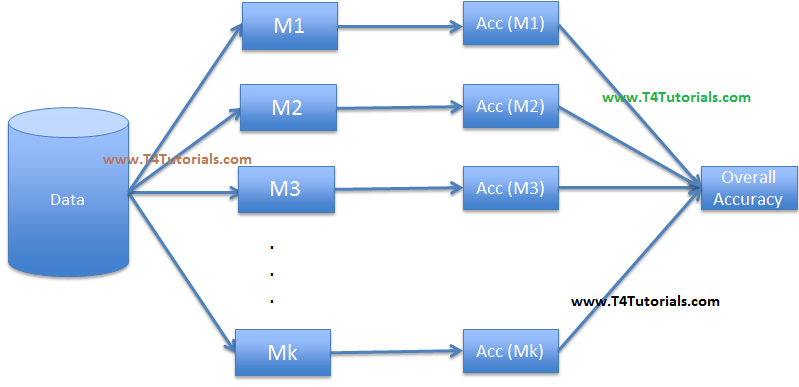
Bagging
Benefits of Bagging
- Can also improve continuous label predictive model’s accuracy
- Ideal for the parallel processing environment
- Significantly greater accuracy than a single classifier
- Reduces the variance of the individual model
- Best in case of diverse classifiers.
Similarities Between Boosting and bagging
- Both of these are ensembling methods to get N learners from 1 learner.
- Both of these perform well when we want to reduce the variance.
- Both of these use random sampling to generate many training data sets.
- Both of these are helpful in making the final decision by averaging the N learners.
Differences and similarities or comparison of boosting and bagging
Differences in boosting and bagging |
Similarities of boosting and bagging |
| Only Boosting determines weights for the data to tip the scales in favor of the most difficult cases. | Both generate several training data sets by random sampling… |
| Only Boosting tries to reduce bias.
Boosting can increase the over-fitting problem. Bagging may solve the over-fitting problem. |
Both are good at reducing the variance.
Both are good at providing higher stability. |
| A weighted average for Boosting and the equally weighted average for Bagging | Both make the final decision by taking the majority of them (or averaging the N learners) |
| Boosting focus is to add new models that do well where previous models fail. | Both are ensemble methods to get N learners from 1 learner… |
| Random forest | Gradient boosting |
Next Similar Tutorials
- Decision tree induction on categorical attributes – Click Here
- Decision Tree Induction and Entropy in data mining – Click Here
- Overfitting of decision tree and tree pruning – Click Here
- Attribute selection Measures – Click Here
- Computing Information-Gain for Continuous-Valued Attributes in data mining – Click Here
- Gini index for binary variables – Click Here
- Bagging and Bootstrap in Data Mining, Machine Learning – Click Here
- Evaluation of a classifier by confusion matrix in data mining – Click Here
- Holdout method for evaluating a classifier in data mining – Click Here
- RainForest Algorithm / Framework – Click Here
- Boosting in data mining – Click Here
- Naive Bayes Classifier – Click Here